
In this post I'll show how to create a document repository with document search, powered by Azure Functions and Cosmos DB. The express purpose of this exercise was to see how much I could build in one day leveraging functions (in truth, I spent a whole second day getting the Cosmos DB code working correctly).
The End Result: What We're Building
We'll end up with a document repository. The documents will be automatically indexed upon upload, allowing them to be searched.
Here's the search UI for the document repository, which you can try out here.

We'll do all this with just a handful of small cloud artifacts: 2 Azure Functions, a Cosmos DB database, and an Azure Blob Storage account. Now that we know what we're building, lets' get to it.
Architecture
Let's discuss the overall architecture. In terms of components, our solution consists of the following:
- Document repository: a container for documents in Azure Blob Storage.
- Index, an Azure Function that automatically indexes any document uploaded to the document repository.
- Query, an Azure Function that carries out document searches whenever requested by the web UI.
- Document metadata, metadata records about documents and the words they contain; implemented in a CosmosDB database.
- Search page, a web site that provides a user interface for searches; implemented as a static web page hosted in Azure Blob storage.

Regarding technology selection, this is something that could have been done in Azure Functions or in AWS Lambda. However, there were several reasons to favor Azure Functions for this particular project:
- The technology I wanted to use for document indexing was Microsoft's IFilter (used for Windows Search): this is only available in Windows. AWS Lambda functions run on Linux, so that would have been a problem.
- Microsoft Visual Studio has strong features supporting Azure Functions. This makes it easy to develop and test them locally, with easy publishing to the cloud.
Document Repository
Our document repository is simply an Azure Blob Storage account to which documents can be uploaded. In this case, we've uploaded a number of public-domain novels from Project Gutenberg, but our documents could just as easily be resumes, mail messages, white papers, homework, presentations, spreadsheets, ...anything at all whether large or small.











The documents I added include public domain classics from Project Gutenberg:
- A Tale of Two Cities
- Alice's Adventures in Wonderland
- Flatland
- Frankenstein
- Grimm's Fairy Tales
- Heart of Darkness
- Moby Dick
- Much Ado About Nothing
- Sherlock Holmes
- The Divine Comedy
- The King James Bible
- The Legend of Sleepy Hollow
- The Time Machine
Notice also we've deliberately got a collection of document types, including Office documents, PDFs, and text files. A document repository and search should be able to handle popular / common document types.
Having the documents stored here, with public read access enabled, will also make it easy to allow a user to download the complete document as it will simpy be an HTTP URL. That will allow a search user to click on a result and have it open on their computer.
Index Function
An Azure Function named Index runs whenever a new or updated document is uploaded to the document repository (blob storage container). This happens because the function has been configured with a Blob Trigger.

The uploaded document blob information is passed to the function. The function saves the content to disk as a tempory file so that it can call a library named IFilterTextReader. IFilterTextReader wraps the Microsoft Windows IFilter API, which is what Windows Search uses to index and search documents. If a document is of a type that IFilter supports (such as an Office document, PDF, text file, or HTML file), the call to IFilterTextReader returns text extracted from the document as a text string free of any special document formatting.
A record is added to the CosmosDB's DocCollection describing the document, including the extracted text:
{
"Category": "docs",
"DocId": "moby-dick.pdf","Name": "moby-dick.pdf",
"DocType": "pdf",
"Size": 3295789,
"Owner": "David Pallmann",
"Words": 220290,
"Text": "The Project Gutenberg EBook of Moby Dick or The Whale by Herman Melville... Call me Ishmael..."
"id": "dc4156db-02e4-44ec-a453-9836006d3574",
"_rid": "rNZTAPIX16YBAAAAAAAAAA==",
"_self": "dbs/rNZTAA==/colls/rNZTAPIX16Y=/docs/rNZTAPIX16YBAAAAAAAAAA==/",
"_etag": "\"25002b49-0000-0000-0000-5c58ca220000\"",
"_attachments": "attachments/",
"_ts": 1549322786
}
With the extracted text of the document, records are added to the DocWordCollection--one for each unique word in the extracted text. These records contain the word being indexed and the name fo the document. For example:
{
"Id": "90995b58-34a3-4cee-b167-983ed1328c84",
"DocId": "moby-dick.pdf",
"Word": "whale",
"id": "bf31a1c2-c506-4074-92cb-cd1ebc15c7bd",
"_rid": "rNZTAOMROvcJAAAAAAAAAA==",
"_self": "dbs/rNZTAA==/colls/rNZTAOMROvc=/docs/rNZTAOMROvcJAAAAAAAAAA==/",
"_etag": "\"170033f2-0000-0000-0000-5c58ca220000\"",
"_attachments": "attachments/",
"_ts": 1549322786
}
Although only distinct words are stored in DocWord records (no repeated words for a document), it is nonetheless a great many records. To reduce the amount of storage, Index uses a trick common in the search engine world: it filters out stop words. Stop words refers to a list of common words like "the" and "and", which have been deemed semantically insignificant. Leaving them out greatly reduces the amount of records stored; the only negative is that a search for these words will not return any results.
Here's the C# code for the Index function:
using System;
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Threading.Tasks;
using Microsoft.Extensions.Logging;
using Microsoft.Azure.WebJobs;
using Microsoft.Azure.WebJobs.Host;
using IFilterTextReader;
using System.Net;
using Microsoft.Azure.Documents;
using Microsoft.Azure.Documents.Client;
using Newtonsoft.Json;
namespace search
{
public static class index
{
private const string EndpointUrl = "https://...CosmosDB endpoint Id....documents.azure.com:443/";
private const string PrimaryKey = "...access-key...P9twYPwfPCwvPpUUIuM7TbkU5zEFPBqUKiWWILANqOjPnjag5tw==";
private static DocumentClient client;
private const bool LogDetail = false;
[FunctionName("index")]
public static void Run([BlobTrigger("docs/{name}", Connection = "AzureWebJobsStorage")]Stream myBlob, string name, ILogger log)
{
log.LogInformation($"Blob trigger: Name: {name}, Size: {myBlob.Length} bytes");
log.LogInformation("---- Start of Job: index " + name);
String tempPath = Path.Combine(Path.GetTempPath(), name);
using (System.IO.FileStream output = new System.IO.FileStream(tempPath, FileMode.Create))
{
myBlob.CopyTo(output);
}
if (LogDetail) log.LogInformation("---- written to disk file " + tempPath + " ----");
String text = ExtractTextFromFile(log, tempPath, null);
if (LogDetail) log.LogInformation("extracted text from file");
log.LogInformation("Text of file extracted");
AddDocumentRecord(log, name, myBlob.Length, text).Wait();
log.LogInformation("---- End of Job: index " + name);
}
#region ExtractTextFromFile
// Extract searchable text from a file using IFilterTextReader.
// Extract text from document, then replace multiple white space sequences with a single space.
// If IFilterTextReader fails (for example, old Office document; or unknown document type), an exception is logged and null is returned.
// Prefix is optional text to prepend to the result - such as document filename, metadata properties, anything else to include in search text.
private static String ExtractTextFromFile(ILogger log, String inputFile, String prefix = null)
{
String line;
String cleanedString = prefix;
try
{
FilterReaderOptions options = new FilterReaderOptions() { };
using (var reader = new FilterReader(inputFile, string.Empty, options))
{
while ((line = reader.ReadLine()) != null)
{
line = line.Trim();
if (!String.IsNullOrEmpty(line))
{
line = System.Text.RegularExpressions.Regex.Replace(line, @"[,]\s+", " ");
line = System.Text.RegularExpressions.Regex.Replace(line, @"[,]", "");
line = System.Text.RegularExpressions.Regex.Replace(line, @"[^a-zA-Z'\d\s:]", " ");
line = System.Text.RegularExpressions.Regex.Replace(line, @"\s+", " ");
cleanedString += line + " ";
}
}
} // end reader
}
catch (Exception ex)
{
log.LogError("ExtractTextFromFile: " + ex.Message);
}
return cleanedString;
}
#endregion
#region AddDocumentRecord
private static async Task AddDocumentRecord(ILogger log, String name, long length, String text)
{
try
{
// https://nlp.stanford.edu/IR-book/html/htmledition/dropping-common-terms-stop-words-1.html
List<String> stopWords = new List<string>();
stopWords.Add("a");
stopWords.Add("an");
stopWords.Add("and");
stopWords.Add("are");
stopWords.Add("as");
stopWords.Add("at");
stopWords.Add("be");
stopWords.Add("by");
stopWords.Add("for");
stopWords.Add("from");
stopWords.Add("has");
stopWords.Add("he");
stopWords.Add("in");
stopWords.Add("is");
stopWords.Add("it");
stopWords.Add("its");
stopWords.Add("of");
stopWords.Add("on");
stopWords.Add("that");
stopWords.Add("the");
stopWords.Add("to");
stopWords.Add("was");
stopWords.Add("were");
stopWords.Add("will");
stopWords.Add("with");
client = new DocumentClient(new Uri(EndpointUrl), PrimaryKey);
// Create database and collection if necessary
await client.CreateDatabaseIfNotExistsAsync(new Database { Id = "SearchDB" });
await client.CreateDocumentCollectionIfNotExistsAsync(UriFactory.CreateDatabaseUri("SearchDB"), new DocumentCollection { Id = "DocCollection" }, new RequestOptions { PartitionKey = new PartitionKey("/Category"), OfferThroughput = 400 });
await client.CreateDocumentCollectionIfNotExistsAsync(UriFactory.CreateDatabaseUri("SearchDB"), new DocumentCollection { Id = "DocWordCollection" }, new RequestOptions { PartitionKey = new PartitionKey("/DocId"), OfferThroughput = 400 });
// From extracted text, create a collection of unique words
String[] items = text.ToLower().Split(new[] { ' ' }, StringSplitOptions.RemoveEmptyEntries);
int wordCount = items.Length;
IEnumerable<String> uniqueWords = items.Distinct();
int uniqueWordCount = uniqueWords.Count();
// Add Document record
String docType = null;
int pos = name.LastIndexOf(".");
if (pos != -1) docType = name.Substring(pos + 1);
Document document = new Document()
{
Category = "docs",
DocId = name,
Name = name,
DocType = docType,
Owner = "David Pallmann",
Size = Convert.ToInt32(length),
Text = text,
Words = text.Split(' ').Length + 1
};
try
{
// Partition key provided either doesn't correspond to definition in the collection or doesn't match partition key field values specified in the document.
log.LogInformation("Creating document - Category: " + document.Category + ", DocId: " + document.DocId); // + name);
await client.CreateDocumentAsync(UriFactory.CreateDocumentCollectionUri("SearchDB", "DocCollection"), document, new RequestOptions() { PartitionKey = new PartitionKey("docs") });
log.LogInformation("Document record created, Id: " + document.DocId);
}
catch (DocumentClientException de)
{
try
{
log.LogInformation("ERROR creating document: " + de.GetType().Name + ": " + de.Message);
// Create document failed, so perform a Replace instead
log.LogInformation("Document exists, Replacing existing document");
var docCollectionUrl = UriFactory.CreateDocumentCollectionUri("SearchDB", "DocCollection");
var docCollection = (await client.ReadDocumentCollectionAsync(docCollectionUrl, new RequestOptions() { PartitionKey = new PartitionKey("docs") })).Resource;
var query = new SqlQuerySpec("SELECT * FROM DocCollection doc WHERE doc.DocId = @DocId",
new SqlParameterCollection(new SqlParameter[] { new SqlParameter { Name = "@DocId", Value = document.DocId } }));
var existingDocRecords = client.CreateDocumentQuery<Microsoft.Azure.Documents.Document>(docCollectionUrl, query, new FeedOptions() { EnableCrossPartitionQuery=true }).AsEnumerable();
if (existingDocRecords != null && existingDocRecords.Count() > 0)
{
Microsoft.Azure.Documents.Document doc = existingDocRecords.First<Microsoft.Azure.Documents.Document>();
doc.SetPropertyValue("Category", document.Category);
doc.SetPropertyValue("DocId", document.DocId);
doc.SetPropertyValue("Name", document.Name);
doc.SetPropertyValue("DocType", document.DocType);
doc.SetPropertyValue("Owner", document.Owner);
doc.SetPropertyValue("Text", document.Text);
doc.SetPropertyValue("Words", document.Words);
await client.ReplaceDocumentAsync(existingDocRecords.First<Microsoft.Azure.Documents.Document>().SelfLink, doc, new RequestOptions() { PartitionKey = new PartitionKey("docs") });
log.LogInformation("Document record replaced, Id: " + document.DocId);
}
}
catch (DocumentClientException de2)
{
log.LogInformation("ERROR replacing document: " + de2.GetType().Name + ": " + de2.Message);
}
}
var collUrl = UriFactory.CreateDocumentCollectionUri("SearchDB", "DocWordCollection");
var doc1 = (await client.ReadDocumentCollectionAsync(collUrl, new RequestOptions() { PartitionKey = new PartitionKey(document.DocId) })).Resource;
var existingDocWordRecords = client.CreateDocumentQuery(doc1.SelfLink, new FeedOptions() { PartitionKey = new PartitionKey(document.DocId) }).AsEnumerable().ToList();
if (existingDocWordRecords != null)
{
int count = 0;
try
{
RequestOptions options = new RequestOptions() { PartitionKey = new PartitionKey(document.DocId) };
log.LogInformation("Deleting prior DocWord records...");
foreach (Microsoft.Azure.Documents.Document word in existingDocWordRecords)
{
if (LogDetail) log.LogInformation("Found document SelfLink: " + word.SelfLink + ", DocId: " + word.GetPropertyValue<String>("DocId") + ", Word: " + word.GetPropertyValue<String>("Word"));
await client.DeleteDocumentAsync(word.SelfLink /* UriFactory.CreateDocumentUri("SearchDB", "DocWordCollection", word.SelfLink) */, options); //, options);
count++;
}
}
catch (DocumentClientException de)
{
log.LogInformation("ERROR deleting DocWord record: " + de.Message);
}
catch (Exception ex)
{
log.LogInformation("EXCEPTION deleting DocWord record: " + ex.GetType().Name + ": " + ex.Message);
if (ex.InnerException != null)
{
log.LogInformation("INNER EXCEPTION: " + ex.InnerException.GetType().Name + ": " + ex.InnerException.Message);
}
}
log.LogInformation(count.ToString() + " DocWord records deleted");
}
// Store document words in Words collection
try
{
log.LogInformation("Adding DocWord records with partition key " + document.DocId + "...");
int count = 0;
DocWord docWord = null;
foreach (String word in uniqueWords)
{
if (!stopWords.Contains(word))
{
docWord = new DocWord()
{
Id = Guid.NewGuid().ToString(),
DocId = document.DocId,
Word = word
};
if (LogDetail) log.LogInformation("About to: CreateDocumentAsync on DocWordCollection: word: " + docWord.Word + ", DocId:" + docWord.DocId);
await client.CreateDocumentAsync(UriFactory.CreateDocumentCollectionUri("SearchDB", "DocWordCollection"), docWord, new RequestOptions() { PartitionKey = new PartitionKey(document.DocId) });
count++;
}
}
log.LogInformation(count.ToString() + " DocWord records created");
}
catch (DocumentClientException de)
{
log.LogInformation("ERROR creating DocWord record: " + de.Message);
}
}
catch (DocumentClientException de)
{
Exception baseException = de.GetBaseException();
log.LogInformation("{0} error occurred: {1}, Message: {2}", de.StatusCode, de.Message, baseException.Message);
}
catch (Exception e)
{
Exception baseException = e.GetBaseException();
log.LogInformation("Error: {0}, Message: {1}", e.Message, baseException.Message);
}
}
#endregion
}
}
index function
The DocWordCollection is what the query function will use to resolve searches.
One concern in a function like Index is whether it can run in the maximum amount of time allowed for an Azure Function (currently 10 minutes). In fact, I found in my testing that while most documents completed in time, my largest text (the King James Bible) timed out before completing. As a result, it is only partially indexed.
This brings up a very important point when you are working on functions: you should test them with your worst-case data to ensure they can complete their work on time. When they can't, you'll need to reconsider how you've architected things. In the case of Index, there are several ways in which that function could be distributed into several functions: for example, extracting the searchable text from a document could be in one function, while adding word records to the DocWord table could be in another separate function. Another alternative would be using Durable Functions arranged in a workflow. Perhaps when I have the time to take this further we'll split Index into several functions; for now, it's fine for the vast majority of the documents I wanted to index.
Query Function
A second Azure Function named Query performs search queries. This function is triggered by HTTP. When a user visits the search page and clicks Search, a request is sent to https://pallmann-search.azurewebsites.net/api/query?search=term, which causes an HTTP trigger to run the Query function.

The function queries the Cosmos DB DocWordCollection for records whose Word field matches the search term (this is done for each word in the search term). The DocId field of each matching record contains the name of the matching document. The matches are returned as a JSON array. Here's the code for the query function:
using System;
using System.Collections.Generic;
using System.Globalization;
using System.Linq;
using System.Net;
using System.Net.Http;
using System.Threading.Tasks;
using Microsoft.Azure.WebJobs;
using Microsoft.Azure.WebJobs.Extensions.Http;
using Microsoft.Azure.WebJobs.Host;
using Microsoft.Azure.Documents;
using Microsoft.Azure.Documents.Client;
using Newtonsoft.Json;
namespace search
{
public static class query
{
private const string EndpointUrl = "https://...Cosmos DB endpoint...documents.azure.com:443/";
private const string PrimaryKey = "access-key...BqUKiWWILANqOjPnjag5tw==";
[FunctionName("query")]
public static async Task<HttpResponseMessage> Run([HttpTrigger(AuthorizationLevel.Anonymous, "get", "post", Route = null)]HttpRequestMessage req, TraceWriter log)
{
log.Info("C# HTTP trigger function processed a request.");
DocumentClient client = new DocumentClient(new Uri(EndpointUrl), PrimaryKey);
// get the search term
string search = req.GetQueryNameValuePairs()
.FirstOrDefault(q => string.Compare(q.Key, "search", true) == 0)
.Value;
if (search == null)
{
dynamic data = await req.Content.ReadAsAsync<object>();
search = data?.name;
}
// If a quoted term was passed such as "the man", set isQuoted flag. This will add an additional level of search
// against the extracted document text for an exact match of the text sequence.
bool isQuoted = false;
if (search.StartsWith("\"") && search.EndsWith("\"") && search.Length > 2)
{
isQuoted = true;
search = search.Substring(1, search.Length - 2);
}
// Query all DocWordCollection records containing the search term - query each word separately
List<String> docs = new List<String>();
try
{
foreach (String term in search.Split(' '))
{
log.Info("Querying for term: " + term);
FeedOptions queryOptions = new FeedOptions { EnableCrossPartitionQuery = true, MaxItemCount = -1 };
IQueryable<DocWord> results = client.CreateDocumentQuery<DocWord>(
UriFactory.CreateDocumentCollectionUri("SearchDB", "DocWordCollection"),
queryOptions)
.Where(m => m.Word == term);
if (results == null || results.Count() == 0)
{
log.Info("Query found no records");
}
else
{
foreach (DocWord rec in results)
{
if (!docs.Contains(rec.DocId)) docs.Add(rec.DocId);
}
log.Info("Query found " + results.Count().ToString() + " records");
}
}
}
catch (DocumentClientException de)
{
log.Info("ERROR during query: " + de.Message);
}
// If search term was in quotes, we must now inspect each potential result match's document record
// and check whether the search query appears exactly or not in the extracted text.
if (isQuoted)
{
try
{
log.Info("Performing additional query for exact search term");
FeedOptions queryOptions = new FeedOptions { EnableCrossPartitionQuery = true, MaxItemCount = -1 };
IQueryable<Document> results = null;
List<String> potentialMatches = docs;
docs = new List<string>();
foreach (String docName in potentialMatches)
{
results = client.CreateDocumentQuery<Document>(
UriFactory.CreateDocumentCollectionUri("SearchDB", "DocCollection"),
queryOptions)
.Where(m => m.DocId == docName);
if (results != null)
{
foreach (Document doc in results)
{
if (doc != null && doc.Text != null &&
(CultureInfo.InvariantCulture.CompareInfo.IndexOf(doc.Text, search, CompareOptions.IgnoreCase))!=-1)
{
if (!docs.Contains(docName)) docs.Add(docName);
}
}
}
}
}
catch(Exception de)
{
log.Info("ERROR during query-quoted: " + de.Message);
}
}
return search == null
? req.CreateResponse(HttpStatusCode.BadRequest, "Please pass a search= term on the query string or in the request body")
: req.CreateResponse(HttpStatusCode.OK, JsonConvert.SerializeObject(docs));
}
}
}
Query Function
Query can hande single-word search terms (such as funeral), multi word search terms (such as england france), and quoted phrases (such as "change in condition"). Let's see how each of these are handled.
A one-word search term queries the DocWord table for the word in question (all normalized to lower-case). Whatever records are returned are the matching documents; the DocId (file name) of each document is returned as an array in the function results.
A multi-word search term works exactly the same way, except that the query to DocWord is repeated for each word in the query. This means there is an implied OR in the query: a search for england france will match documents containing england or france.
Lastly, there is a quoted phrase, such as "change in condition", whose meaning is find this exact sequence of words together. This kind of query is initially handled just like the multiple word search term logic just described: a collection of documents containing any of the search words is assembled by querying the DocWord table. Next, each potential document match has its master DocCollection record read, which contains the extracted text of the document in its Text field. Only if the full original search term is found in the extracted text will the search result be passed on.
There was not time in this one-day exercise to tackle boolean operators like AND, OR, and NOT; but this could be accomplished easily enough with some additional work; no data structure changes would be needed.
Search UI
For our search user interface, I created a very simple HTML page with some jQuery. This static web page is hosted in Azure blob storage at http://pallmannsearch.blob.core.windows.net/site/search.html.
For example, if we search for a very specific term, "Rumpelstiltskin", we would only expect one hit on Grimm's Fairy Tales; and that's what we get:

Search results for: rumpelstiltskin
If we click the link, that document opens and we can see that it does indeed contain the word "Rumpelstiltskin".

Likewise, a term like "Cheshire" would only match Alice's Adventures in Wonderland, which has a character named the Cheshire Cat:

Search results for: Cheshire
Likewise, I fully expected a search for "Ichabod" to match only The Legend of Sleepy Hollow, whose main character is named Ichabod Crane. To my delight, the search engine also returned a result for Grimm's Fairy Tales. Upon viewing the document, sure enough, there is a character named Ichabod. That is the point of search engines, to bring you new information!

Search results for: Ichabod
If we search on a more widely-used term such as "farmer" or "victor" or "large", we get multiple results:

Search results for: farmer
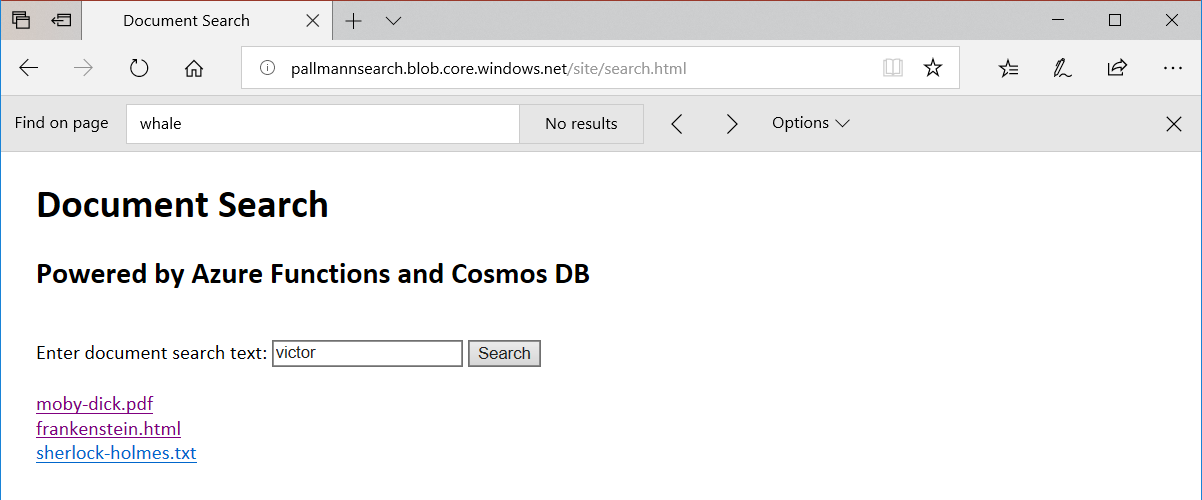
Search results for: victor

Search results for: large
If our search term contains multiple words, we get all documents containing any of those words:

And finally, if our search term is enclosed in quotation marks we get exact matches to the phrase:

Here's the Search page code.
In terms of the final experience, I think the search page, while simple, delivers on expectations. From a performance standpoint, you'll see response times vary: an initial search might take 8 seconds, while a repeat search might only be 0.16 seconds. This has to do with whether or not the Azure Function query is warmed up or not from recent use; if not, you'll have some extra seconds of wait time. And, our Cosmos DB is set to the lowest throughput setting in order to keep costs down.

Search results for: ahab kurtz watson
And finally, if our search term is enclosed in quotation marks we get exact matches to the phrase:

Search results for: "without thinking"
<!DOCTYPE html>
<html lang="en" xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Document Search</title>
<script src="https://code.jquery.com/jquery-2.2.4.min.js"
integrity="sha256-BbhdlvQf/xTY9gja0Dq3HiwQF8LaCRTXxZKRutelT44="
crossorigin="anonymous"></script>
</head>
<body style="font-family: Calibri;Arial;Helevetica">
<div style="margin: 20px">
<div style="font-size: 40px; font-weight: bold; vertical-align: top"><img src="search-azurefunc-logo.png" style="height: 32px; vertical-align: middle" /> Document Search</div>
<div style="font-size: 24px; font-weight: bold; vertical-align: top">Powered by Azure Functions and Cosmos DB</div>
<br/>
<div>
<input id="search-text" type="text" style="width: 350px; padding: 8px" placeholder="Enter a search term" />
<button style="background-color: #3899C6; color: white; padding: 10px; font-weight: bold" onclick="search()">Search</button>
</div>
<br/>
<div id="results">
</div>
</div>
<script>
$(document).ready(function () {
$("#search-text").on("keyup", function (e) {
if (e.keyCode == 13) {
search();
}
});
});
function search() {
var startTime, endTime;
startTime = startTime = new Date();
var query = $('#search-text').val().toLowerCase();
if (!query) return;
var url = "http://pallmann-search.azurewebsites.net/api/query?search=" + query;
$('#results').html('Searching...');
$.ajax({
type: 'GET',
url: url,
accepts: "text/xml",
}).success(function (data) {
endTime = new Date();
var timeDiff = endTime - startTime; //in ms
if (timeDiff > 0) {
timeDiff /= 1000.0;
}
var seconds = timeDiff.toFixed(2);
var array = eval(data);
var html = '';
if (array != null && array.length > 0) {
for (var i = 0; i < array.length; i++) {
html = html + '<a href="http://pallmannsearch.blob.core.windows.net/docs/' + array[i] + '" target="_doc">' + array[i] + '</a><br/>';
}
}
else {
html = 'No matches<br/>';
}
html = html + '<br/>Search time: ' + seconds.toString() + ' seconds';
$('#results').html(html);
}).error(function (e) {
//console.log(e);
});
}
</script>
</body>
</html>
search.html
In terms of the final experience, I think the search page, while simple, delivers on expectations. From a performance standpoint, you'll see response times vary: an initial search might take 8 seconds, while a repeat search might only be 0.16 seconds. This has to do with whether or not the Azure Function query is warmed up or not from recent use; if not, you'll have some extra seconds of wait time. And, our Cosmos DB is set to the lowest throughput setting in order to keep costs down.
Given some additional time, there are more features that could be added:
- Store document metadata, including title, author, and year of publication, and show in results
- Show excerpts of the text in search results with the search term highlighted
- Add support for boolean operators in search queries
- Refactor functions to support indexing really large documents without timing out
Configuration
In order to make all of this work, some configuration was needed:
1. To allow the Index function as much time as possible to run, the function code's host.json file had a setting added to set the maximum runtime permitted which is currently 10 minutes:
{
// Value indicating the timeout duration for all functions.
// In Dynamic SKUs, the valid range is from 1 second to 10 minutes and the default value is 5 minutes.
// In Paid SKUs there is no limit and the default value is null (indicating no timeout).
"functionTimeout": "00:10:00"
}
2. For the search web page to be able to access the function over HTTP, a CORS permission for the storage account domain hosting the search page had to be added. This was configured in the App Services area for the pallmann-search Azure Function app. Without this permission, the web site's attempt to invoke the Query function over HTTP results in a CORS error.
3. By default, the Cosmos DB will index every field of the records we store. We don't want the DocCollection's /Text field indexed, because it is really large (all the extracted text from the document, many thousands of words). We don't want to waste storage space indexing it. To tell Cosmos DB not to index the /Text column, we go to Scale & Settings for DocCollection in the Azure Portal and add an ExcludePath directive to the Indexing Policy JSON:
{
...
"excludedPaths": [ { "path": "/\"_etag\"/?" }, { "path": "/\"Text\"/?" } ] }
3. By default, the Cosmos DB will index every field of the records we store. We don't want the DocCollection's /Text field indexed, because it is really large (all the extracted text from the document, many thousands of words). We don't want to waste storage space indexing it. To tell Cosmos DB not to index the /Text column, we go to Scale & Settings for DocCollection in the Azure Portal and add an ExcludePath directive to the Indexing Policy JSON:
{
...
"excludedPaths": [ { "path": "/\"_etag\"/?" }, { "path": "/\"Text\"/?" } ] }
In Conclusion
You can try out the search engine at http://pallmannsearch.blob.core.windows.net/site/search.html. The source code is at GitHub/davidpallmann/doc-search-azure; to deploy it, you'll need to allocate your own cloud assets and provide your own access keys).
I greatly enjoyed this time-boxed exercise. I'd suspected functions would work well for a document search engine, and it turns out they do. There are some changes needed to support really large documents, but the way to proceed is understood. The Azure Portal nicely provides a way to view the log output from functions. Using this, you can see your functions trigger and execute. This turned out to be an invaluable tool for debugging.
This was also a chance to spend some time with Cosmos DB. There was a fairly large learning curve involved: although I understood the core concepts like partition keys and Ids readily enough, it took an extra day to learn the methods and patterns sufficiently and get the code working right. It was particularly tough handling repeat documents (the same name document uploaded a second time) and clearing out prior data; but I eventually got there.
Despite my learning-curve time with Cosmos DB, the overall rate of development was extremely rapid and satisfying. This is a testimony to the first-rate development experience that Azure Functions provides. If you have a good notion of what it is you want to create, Azure Functions can take you from concept to reality in no time at all.
If you play with the demo, you'll likely encounter a varying range of search times. One reason for that is whether or not there's an already-warmed-up instance of the Query function ready and waiting. Another is that I'm keeping the Cosmos DB on its slowest (cheapest) throughput setting. Rest assured that this would sizzle in a Production setting and scale well.
No comments:
Post a Comment